Fortieth International Conference on Machine Learning (ICML) 2023: Demonstration-free Autonomous Reinforcement Learning via Implicit and Bidirectional Curriculum
[Paper] [Video] [Bibtex] [Code]
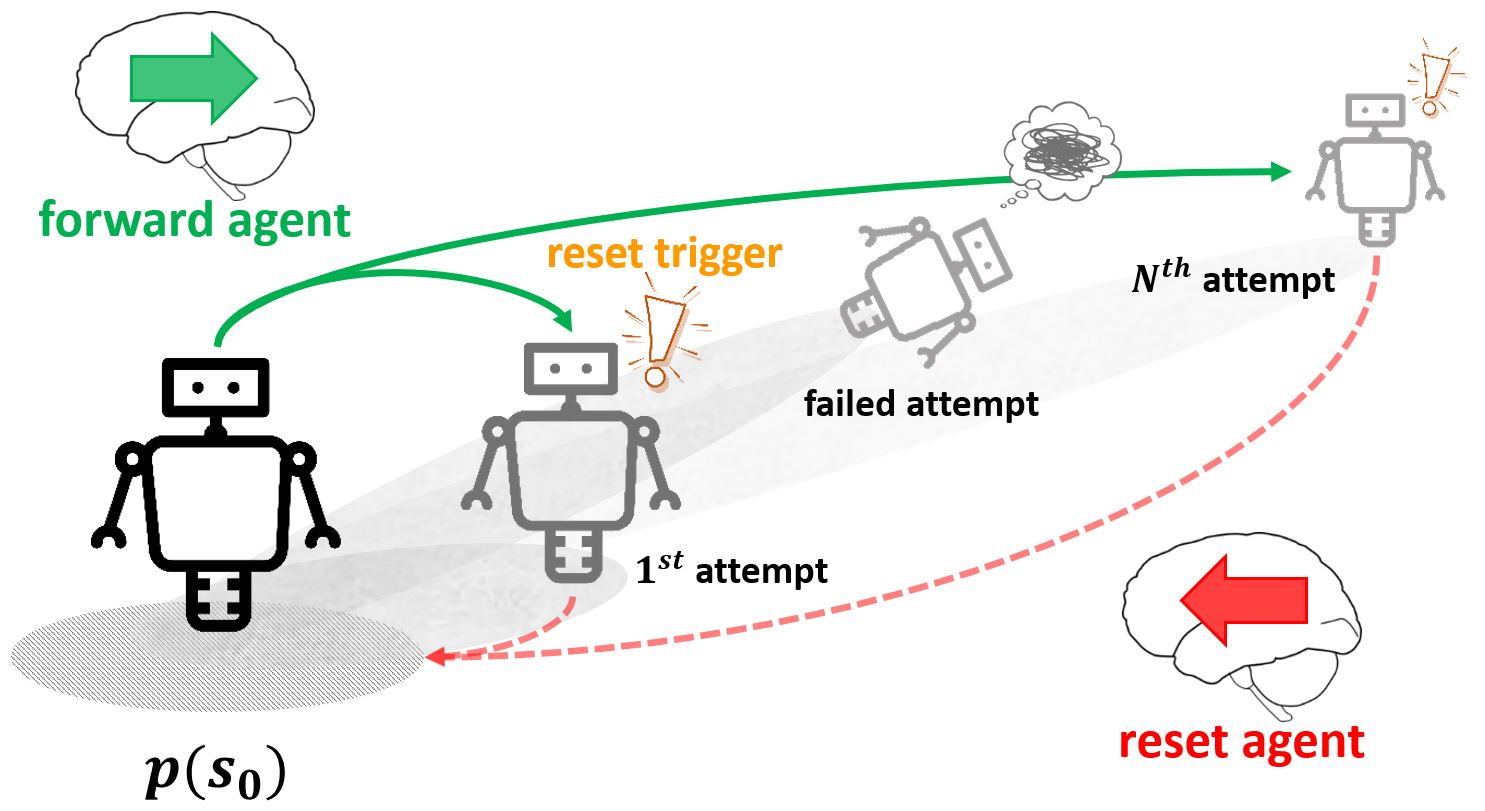
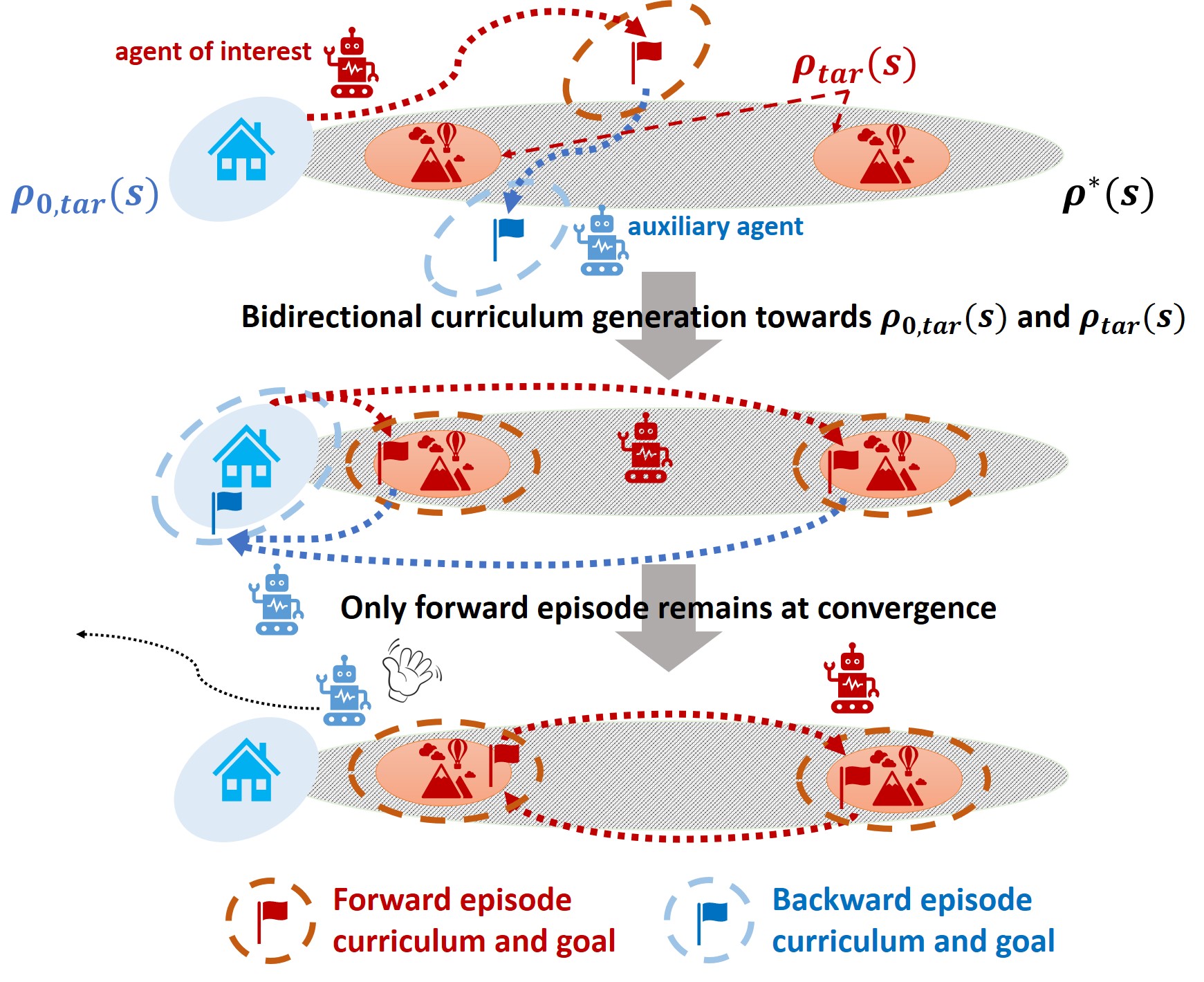
While reinforcement learning (RL) has achieved great success in acquiring complex skills solely from environmental interactions, it assumes that resets to the initial state are readily available at the end of each episode. Such an assumption hinders the autonomous learning of embodied agents due to the time-consuming and cumbersome workarounds for resetting in the physical world. Hence, there has been a growing interest in autonomous RL (ARL) methods that are capable of learning from non-epis...